
Materials
Motivation
之前的GCN方法将中心节点的信息和K-th neighborhood进行传播,但是认为每个邻接节点的权重是相同的。这篇工作enables (implicitly) specifying different weights to different nodes in a neighborhood, without requiring any kind of costly matrix operation (such as inversion) or depending on knowing the graph structure upfront. In this way, we address several key challenges of spectral-based graph neural networks simultaneously, and make our model readily applicable to inductive as well as transductive problems.
其中的inductive learning problem 包括了 tasks where the model has to generalize to completely unseen graphs. 广义的inductive learning和deductive learning相对:前者指的是给出例子进行归纳从而找到规律;后者指的是给出规则,让学习者运用规则到特定的例子上。
Architecture
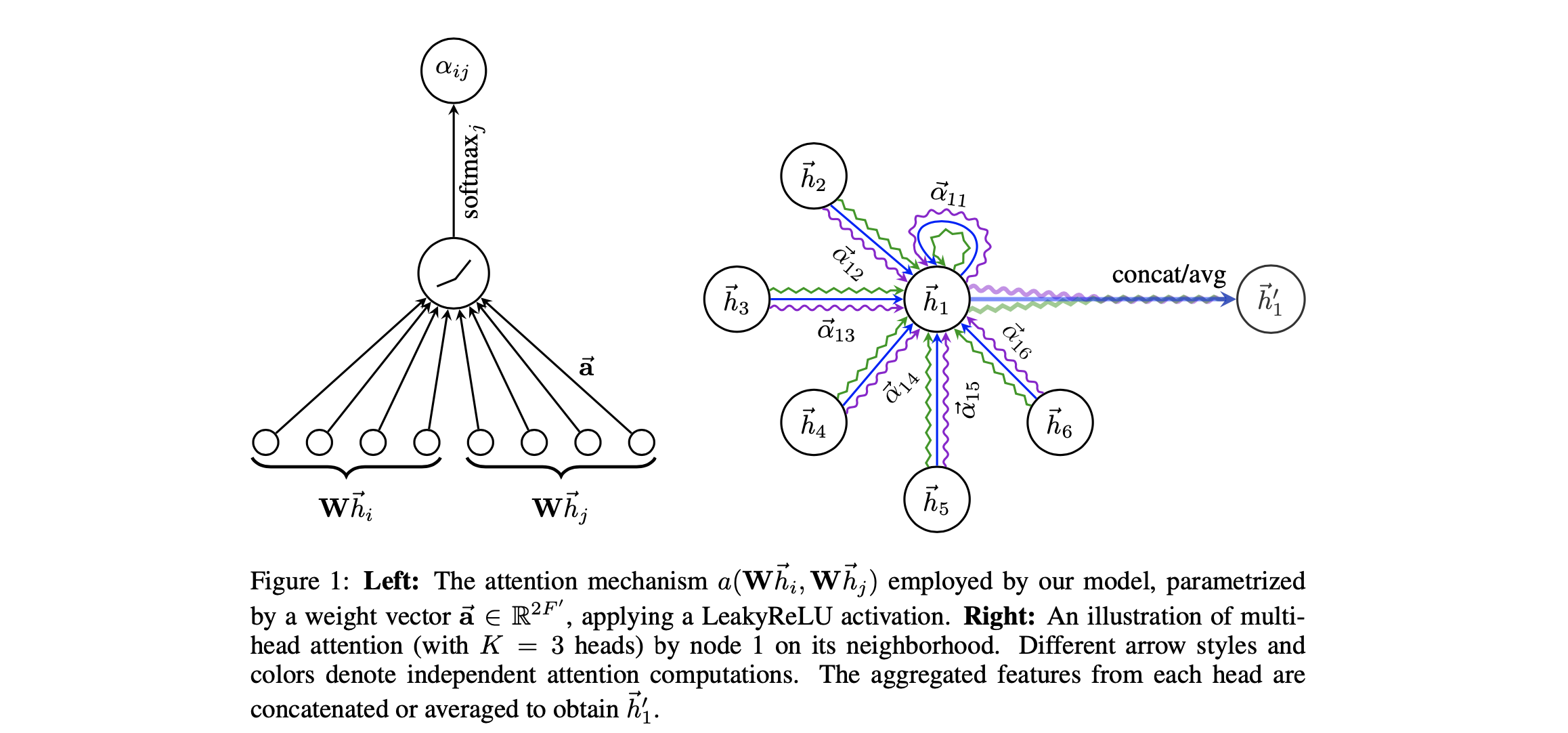
在GAT中,这章描述的Graph Attention Layer会从始至终被使用。首先文章采用了一个在节点空间中共享的映射矩阵$W$,两个节点之间的相关性$e_{ij}$通过这个矩阵加上一个函数$a$进行度量,其中$a$是一个参数化的函数:
需要注意的是,我们可以将这个相关性计算apply到图中的任意两个节点上而不去考虑图本身的结构。但是一般来说Attention机制被应用在1st-order neighborhood(需要注意的是中心节点在本文也被定义在1st-order neighborhood内)上,经过归一化我们有:
最后输出层的节点表示$\vec{h}_{i}^{\prime}$为:
为了让self-attention在训练的时候更加稳定,可以使用Multi-head的技术。最后的表示就是多个头结果的concatenation:
特别地,在整个网络的最后一层预测层再进行concatenation是不make sense的。通过average和延后的non-linear层我们有:
Discussion and Future Work
The time complexity of a single GAT attention head computing $F^\prime$ features may be expressed as $O(|V|FF^\prime + |E|F^\prime)$, where F is the number of input features. 因为这仅仅是一个head的计算复杂度,可以看到还是相对较高的。
未来可以关注的方向有:
- overcoming the practical problems to be able to handle larger batch sizes.
- take advantage of the attention mechanism to perform a thorough analysis on the model interpretability.
- extend the model to incorporate edge features (possibly indicating relationship among nodes) .