
Materials
Motivation
在self-supervised learning方法中非常流行的contrastive learning大量依赖负样本的采样方法和batch size. 本工作的动机基于一个随机的发现:首先随机初始化了一个网络,这个网络得到的representation (on top of which is a mere linear classifier) 在ImageNet上仅仅取得了$1.4\%$ 的top-1 accuracy. 然后将这个网络的representation作为target network,接着训练一个online network去拟合这个target network, 得到的online network可以在ImageNet上得到$18.4\%$ top-1 accuracy. 这说明了self-bootstraping可能是一个很好的优化目标:将新得到的online network作为新的target network, 然后接着初始化一个新的online network去拟合target network. 重复这个过程就有可能得到质量不断提升的representation. 在实践中,BYOL采用的是”Exponential Moving Average (EMA) of the online network”.
Methods
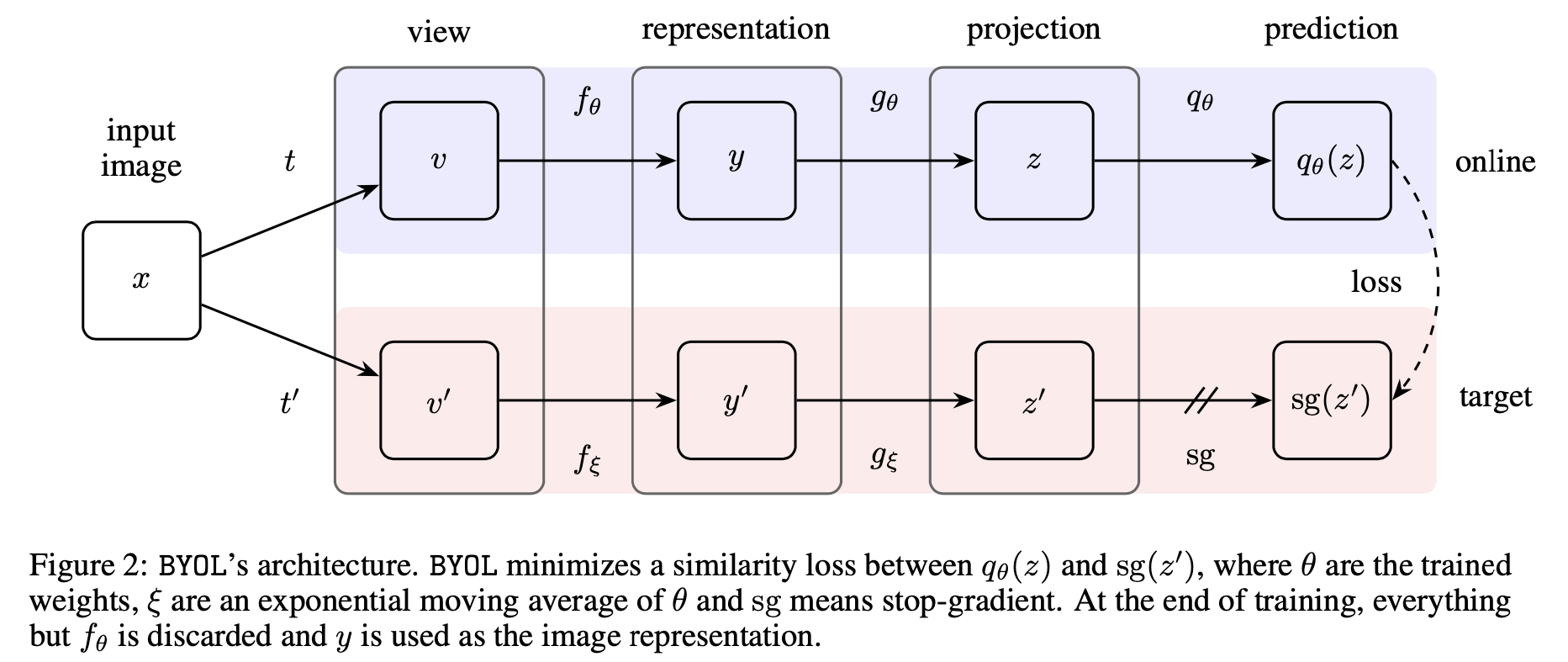
BYOL的目标是学习到$f_\theta$将原有的input映射到representation space.
Online network 由参数 $\theta$ model的,共有三个阶段:首先从原有的input image选取一个view (由具体的data augmentation方案决定);接着分别通过encoder $f_\theta$, projector $g_\theta$ and a predictor $q_\theta$.
Target network 的架构和online network相同,参数 $\xi$ 是exponential moving average of the online parameters: given a target decay rate $\tau \in[0,1]$, we update $\xi$ as follows
最终的loss就是一个regression task, 其中 $\operatorname {sg}(z^\prime)$ 意思是stop-gradient, 以下等式的中间项表示在projector空间经过normalize之后的regression loss. (作者表示虽然可以直接在representation空间进行预测,但是前人工作SimCLR已经证明了使用projection会有更好的表现)
同时为了对称化以上的loss term,作者将两个view $v, v^\prime$ 互换位置代入 online network 和 target network得到 $\widetilde{\mathcal{L}}_{\theta}^{\mathrm{BYOL}}$ . 每一个step仅仅只用 $\mathcal{L}_{\theta}^{\mathrm{BYOL}}+\widetilde{\mathcal{L}}_{\theta}^{\text {ВУОС }}$ update online network的参数.
Implementation

Experiments
评价representation的quality可以在两个方面进行:首先将representation空间fix住然后将其输入一个linear classifier. 其次可以将representation的encoder作为网络的初始化参数,在部分的training set上做fine-tuning,可以被归类到semi-supervised learning上. 另外本文还测试了将模型向不同的数据集进行迁移得到的不同效果.
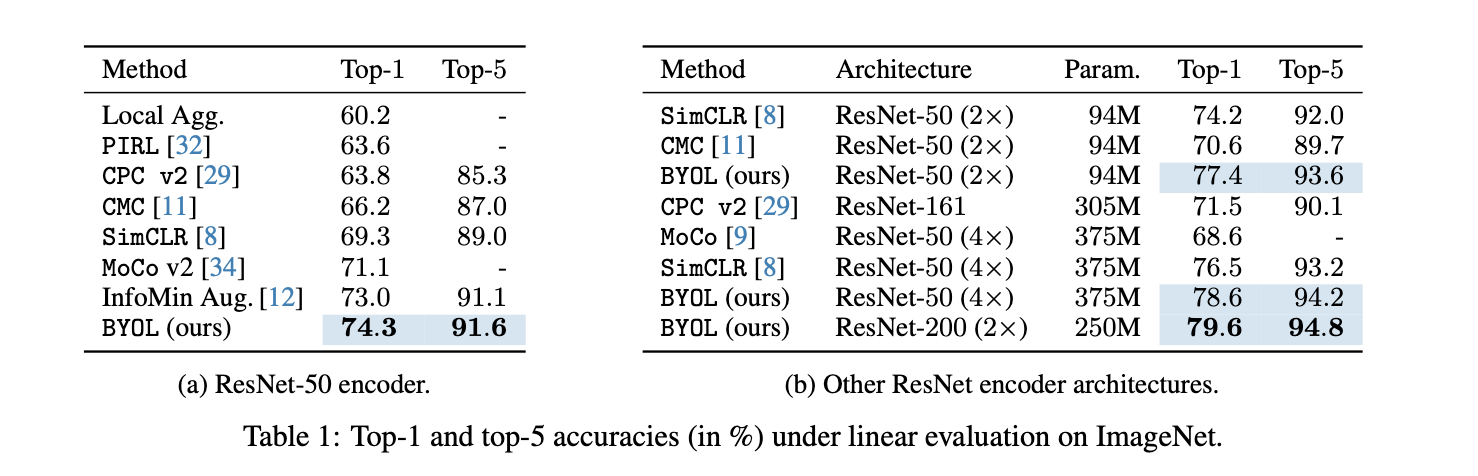
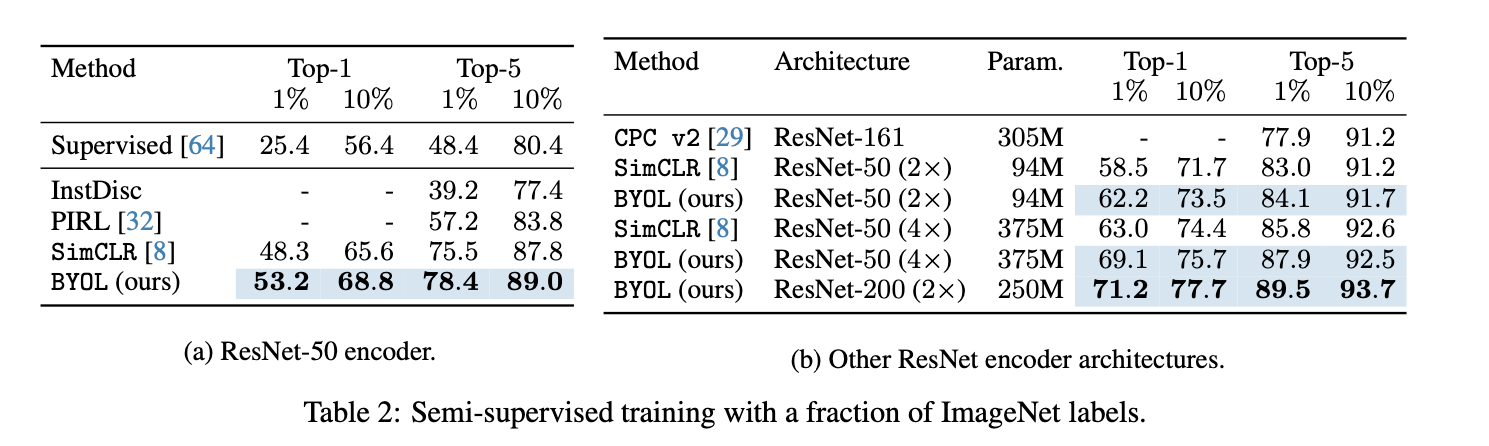
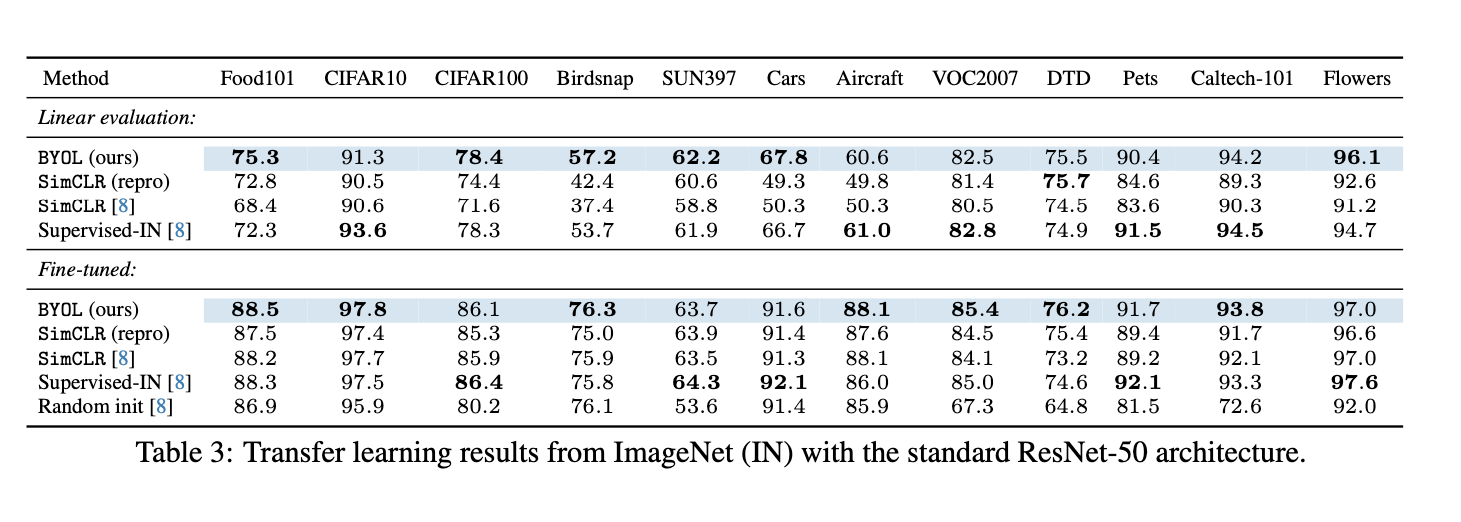
Ablations
More robust for smaller batch size and less image augmentation (compared to CL).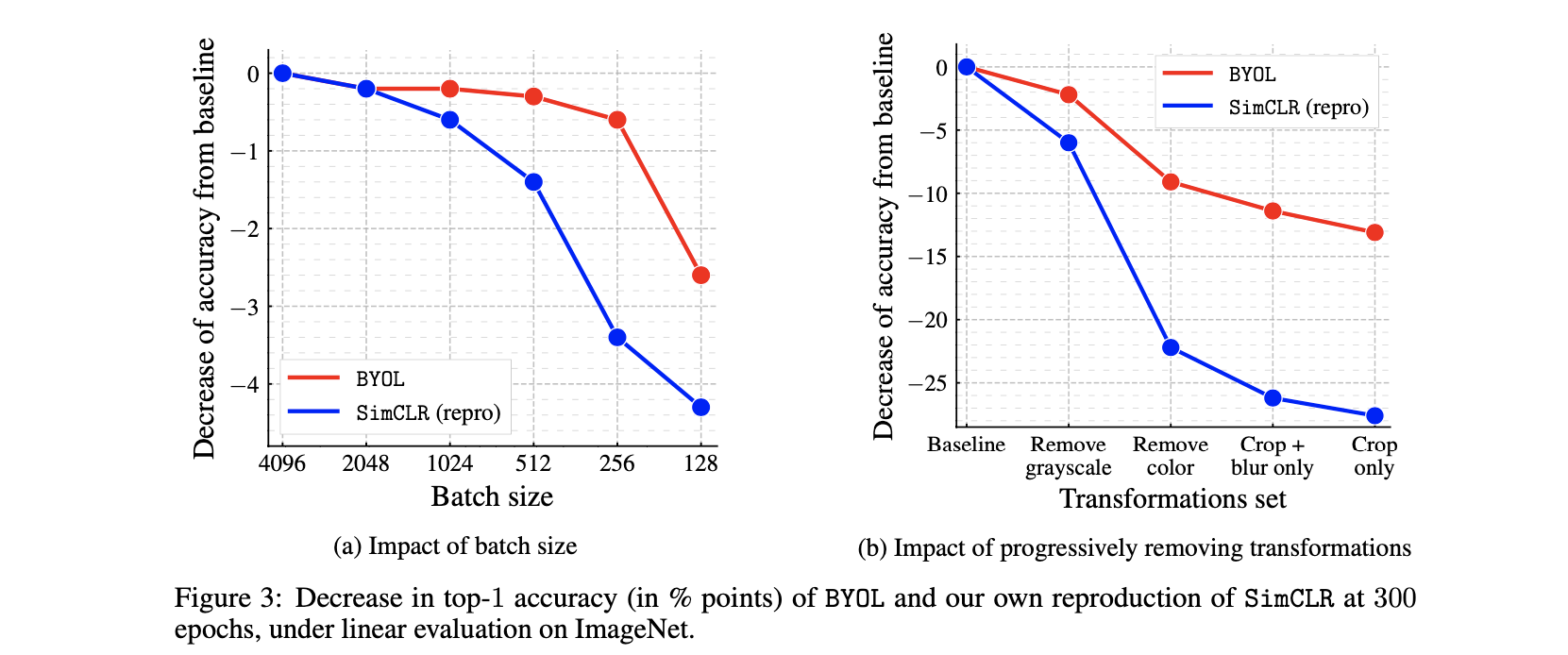
该方法对于target network的保留权重 $\tau$ 较为敏感.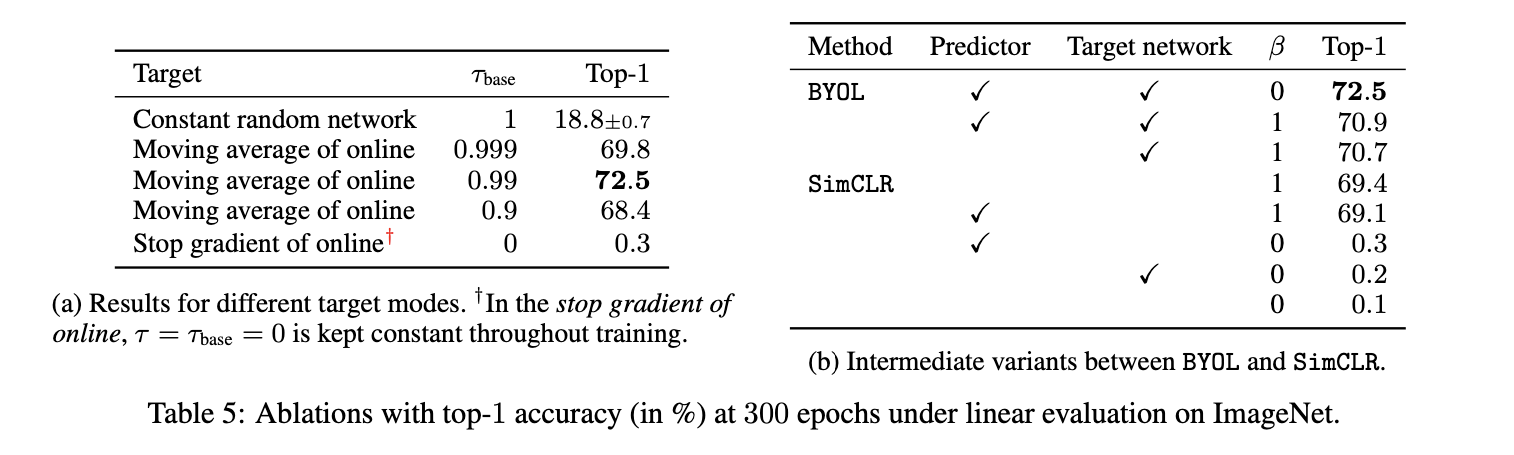
Conclusion
Nevertheless, BYOL remains dependent on existing sets of augmentations that are specific to vision applications. To generalize BYOL to other modalities (e.g., audio, video, text, . . . ) it is necessary to obtain similarly suitable augmentations for each of them. Designing such augmentations may require significant effort and expertise. Therefore, automating the search for these augmentations would be an important next step to generalize BYOL to other modalities.