Materials
Motivation
From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. We present Momentum Contrast (MoCo) as a way of building large and consistent dictionaries for unsupervised learning with a contrastive loss.
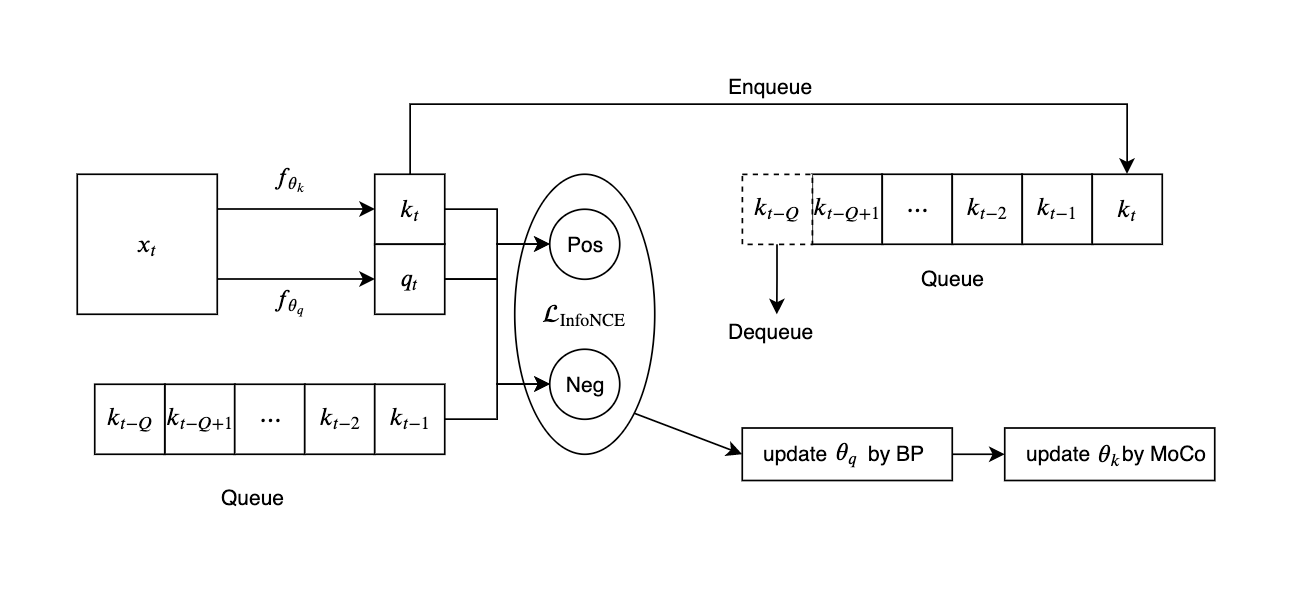
We maintain the dictionary as a queue of data samples: the encoded repre- sentations of the current mini-batch are enqueued, and the oldest are dequeued. The queue decouples the dictionary size from the mini-batch size, allowing it to be large.
More- over, as the dictionary keys come from the preceding sev- eral mini-batches, a slowly progressing key encoder, imple- mented as a momentum-based moving average of the query encoder, is proposed to maintain consistency.
Methods
Contrastive Learning as Dictionary Look-up
Consider an encoded query $q$ and a set of encoded samples $\{k_0, k_1, k_2, \cdots \}$ that are the keys of a dictionary. 假定只有一个和 query $q$ 匹配的 key $k_+$, 那么contrastive loss InfoNCE 为以下形式:
其中 $\tau$ 为temperature hyper-parameter. 直觉上来看我们可以将以上loss看做是 (K+1)-way softmax-based classifier that tries to classify $q$ as $k_+$. 其中 $q=f_q(x^q)$ 和 $k=f_k(x^k)$ 分别由encoder $f_q$ 和 $f_k$ 编码得到,两者的encoder可以采取 identical/parameter-sharing/different 这三种模式,通常在contrastive learning的语境下会采取最前者。
Momentum Contrast
从这个角度来说,CL可以被看做为每一个input value $x$ 建立一个key,从而我们有字典 $\{\operatorname{key:} f_k(x);\operatorname{val:}x\}$. MoCo的关键假设是:
Our hypothesis is that good features can be learned by a large dictionary that covers a rich set of negative samples, while the encoder for the dictionary keys is kept as consistent as possible despite its evolution.
MoCo 将 dictionary 看作 “a queue of data samples”. 这样可以将dictionary size设置得比 mini-batch size要大得多从而非常显著地提升负样本的数量:这是因为mini-batch要求内存能够容纳 $\operatorname{mini-batch}\times\operatorname{image-size}$, 而对于queue来说内存需要容纳 $\operatorname{queue-size}\times\operatorname{key-size}$. 非常显然的key的大小远远小于input image. queue 更新的规则是最近的mini-batch of samples替换最早的mini-batch.
将 $f_q$ 直接作为 $f_k$ 会导致表现变得很差。We hypothesize that such failure is caused by the rapidly changing encoder that reduces the key representations’ consistency. We propose a momentum update to address this issue. 以下为momentum update的具体形式:
其中通过BP学习的参数只有 $\theta_q$. In experiments, a relatively large momentum (e.g., m = 0.999, our default) works much better than a smaller value (e.g., m = 0.9), suggesting that a slowly evolving key encoder is a core to making use of a queue.
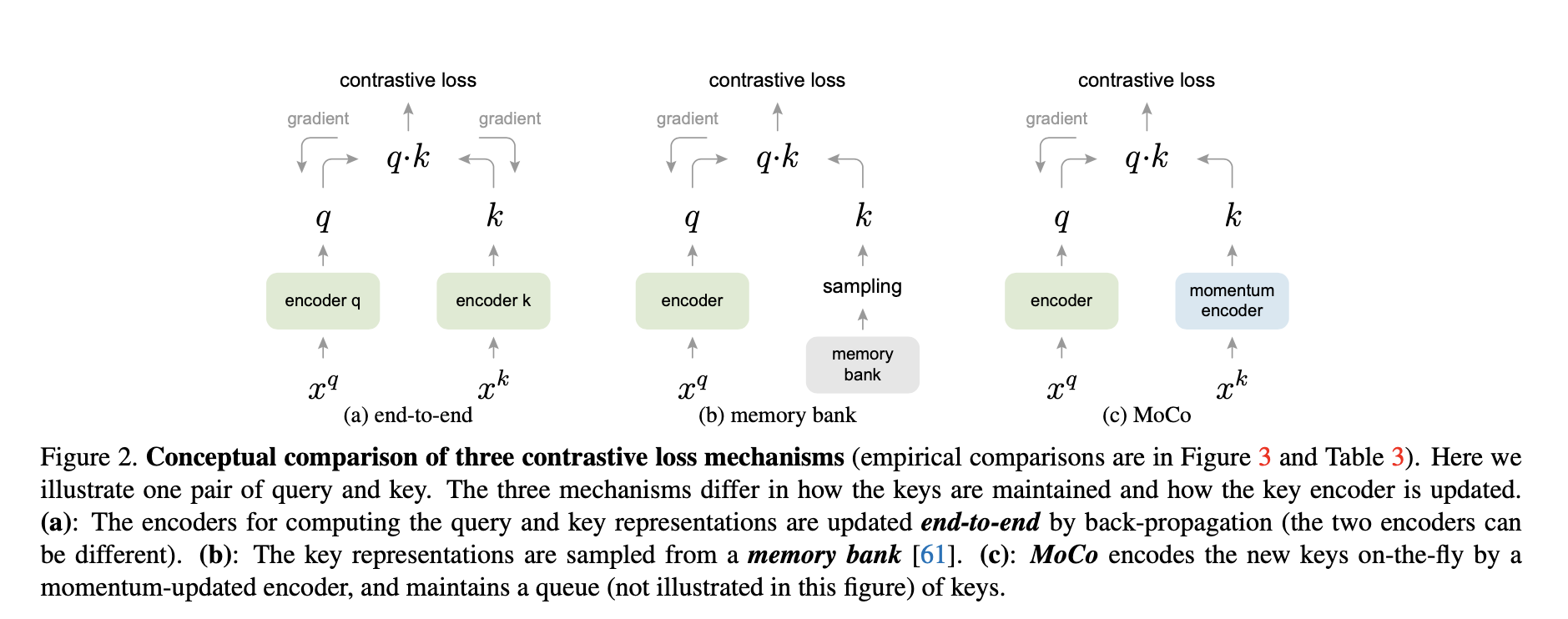
下图表示了mini-batch/memory bank/MoCo架构的区别.
下面的类torch伪代码则展示了整个MoCo的训练过程:
1 | # f_q, f_k: encoder networks for query and key # queue: dictionary as a queue of K keys (CxK) # m: momentum |
为了更好地理解MoCo的更新过程,绘制MoCo示意图如下: